一、前言
在逆向过程中有一个Hook神器是必不可少的工具,之前已经介绍了Xposed和Substrate了,在不同场景下面这两个框架工具具备各自的用途,当然Xposed现在也是我最常用的框架工具,不了解的同学可以看这两篇文章:Android中Hook神器Xposed工具介绍 和 Android中Hook神器SubstrateCydia工具介绍 这两篇文章非常重要一个是Hook Java层的时候最常用的Xposed和Hook Native层的SubstrateCydia,可以看我之前的文章比如写微信插件等都采用了Xposed工具,因为个人觉得Xposed用起来比较爽,写代码比较方便。而对于SubstrateCydia工具可以Hook Native层的,本文会介绍一下如何使用。那么有了这两个神器为啥还要介绍Frida工具呢?而且这个工具网上已经有介绍了,为什么还有介绍了,因为这个Frida工具对于逆向者操作破解来说非常方便,所谓方便是他的安装环境和配置要求都非常简单兼容性也非常好,因为最近在弄一个协议解密,无奈手机上安装Cydia之后不兼容导致死机所以就转向用了这个工具实现了hook,所以觉得这个工具非常好用就单独介绍一下。
二、环境安装配置
因为网上的确有介绍了,而且官网也有文档说明:https://www.frida.re/docs/javascript-api,但是最重要的是片段化就是东一处西一处,没有归纳性的总结,而且很多常用的功能都没介绍,所以本文就把常用的hook工具详细介绍一下,主要从以下几个方面来介绍:
第一、如何修改Java层的函数参数和返回值
第二、如何打印Java层的方法堆栈信息
第三、如何拦截native层的函数参数和返回值
对于Java层会注重介绍,因为我们用过Xposed工具之后都知道,比如参数是自定义类型怎么Hook等。不多说了直接用一个案例作为样本进行操作,为了能够覆盖所有的操作可能性案例需要写的复杂点:
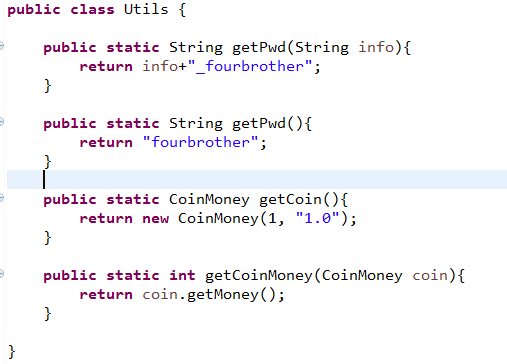
参数和返回值有基本类型,也有自定义类型,接下来我们就开始我们的Frida之旅吧。
这个网上都已经有教程了,因为Frida大致原理是手机端安装一个server程序,然后把手机端的端口转到PC端,PC端写python脚本进行通信,而python脚本中需要hook的代码采用javascript语言。所以这么看来我们首先需要安装PC端的python环境,这个没难度直接安装python即可,然后开始安装frida了,直接运行命令:pip install frida
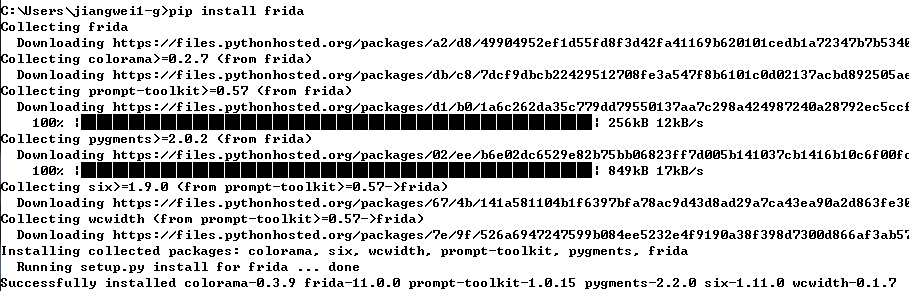
前提是你需要配置好python环境变量,不然提示pip命令找不到。安装完成之后,我们再去官网下载对应版本的手机端程序frida-server:https://github.com/frida/frida/releases 注意这里一定要把frida-server版本和上面PC端安装的frida版本一致,不然运行报错的。其实这里看到真的实现hook功能的是手机端的frida-server,这个也是开源的大家可以研究他的原理。我们也看到这个工具和IDA是不是很类似,也是把手机端的端口转发到PC端进行通信而已。有了frida-server之后就好办了,直接push到手机目录下,然后修改一下文件的属性即可:
adb push /data/local/tmp frida-server
root# chmod 777 /data/local/tmp/frida-server
然后直接运行这个程序:
/data/local/tmp# ./frida-server

然后把端口转发到PC端:
adb forward tcp:27042 tcp:27042
adb forward tcp:27043 tcp:27043

到这里我们就把通信的手机端工作做完了,是不是感觉和Xposed相比非常方便,兼容性非常好,不需要安装Xposed等工具考虑系统手机等适配问题了。接下来就开始在PC端开始编写hook程序进行操作了:
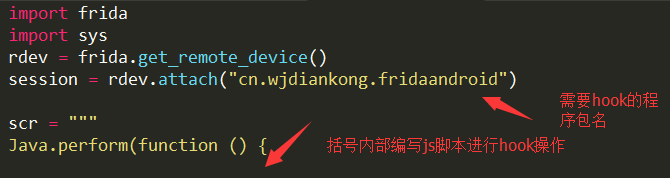
这里代码也非常简单,因为安装好了frida模块,直接导入模块,然后调用api获取设备的session然后hook程序包名,接着就可以执行js脚本代码进行hook操作,然后打印消息:

这里用了python的print函数打印,其实如果想要打印可以在上面的js脚本中使用console.log也是可以的,看自己的习惯了。所以这里我们看到脚本的大致流程就是最外面用python引用frida库进行和设备通信,然后编写js脚本执行hook操作。所以这里最主要的还是js脚本也就是需要理解js语法了。不过这个没啥难度的。好了以上的准备条件都弄完了,下面就开始分部拆解操作看看如何涵盖我们平常使用的hook案例。
三、Java层Hook操作案例分析
第一个案例:hook类的构造方法
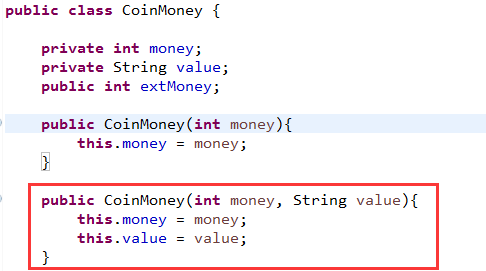
我们有时候想hook一个类的构造方法,在Xposed中直接用findConstructor方法就可以了,因为构造方法可能有多种重载形式,所以需要用参数作为区分,这里我们hook我们案例的CoinMoney类的构造方法:
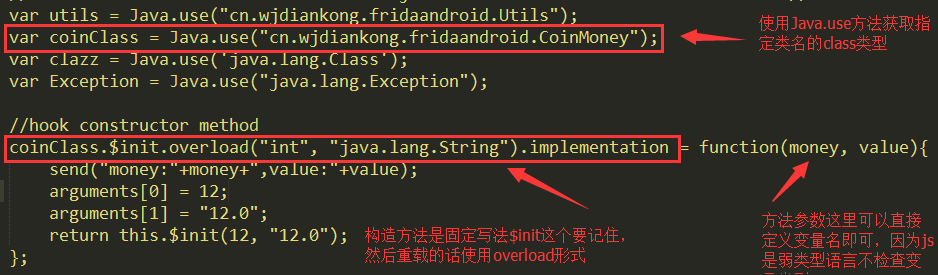
首先脚本中使用Java.use方法通过类名获取类类型,然后构造方法是固定写法:$init;这个要记住,然后因为需要重载所以用overload(……)形式即可,参数和参数之间用逗号隔开即可。后面就是拦截之后的操作了,这里方法参数可以自定义变量名,因为js是弱语言,不对类型做强检查,当然这里还有其他获取参数的方法后面会介绍。这里CoinMoney类的构造方法:
然后我们这里使用send来发送打印消息即可,当然也可以用console.log形式打印日志,代码编写完了,下面就开始运行看效果,运行也很简单,直接python frida.py:
在这之前一定要先打开hook的应用,不然会报错提示找不到这个程序进程:
这时候在运行看到了就成功了,我们把构造方法的参数打印出来了,那么这里hook就成功了。所以可以看到这个操作是不是比Xposed工具更方便呢。但是他也有弊端后面会总结的。
第二、hook类的普通方法
这里的普通方法包括了静态方法,私有方法和公开方法等,这个操作和上面的构造方法其实很类似,代码如下:
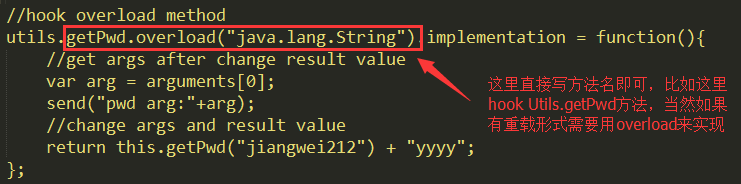
这个就是把构造方法的固定写法$init改成了需要hook的方法名即可。如果方法有重载形式还是用overload进行区分即可,比如这里我们hook了Uitls.getPwd(String pwd)方法:
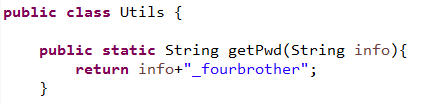
然后这里我们看到可以用一个隐含的变量arguments获取参数,这个是保存了方法的参数信息是系统自带的。所以我们有两种方式获取方法的参数信息。运行看一下效果:

看到打印消息,hook成功了。所以这里就把hook方法获取参数的案例都介绍完了,总结一下很简单,构造方法使用固定写法$init,其他方法全部用方法名即可。如果方法有重载形式需要用overload形式操作参数用逗号分隔。获取参数可以自定义参数名或者用系统隐含的arguments变量获取。当然在这之前都需要用Java.use通过类名获取类型。
第三、修改方法的参数和返回值
我们在使用Xposed进行hook的时候最常用的可能就是修改参数和返回值来实现插件和外挂功能了,在Frida中其实也可以做到但是和Xposed不一样,我们从上面的代码可以看到,没有像Xposed的before方法和after方法,而Frida直接是你可以在function中调用原来的方法这样来进行参数修改,比如这里我要修改上面的方法参数和返回值:
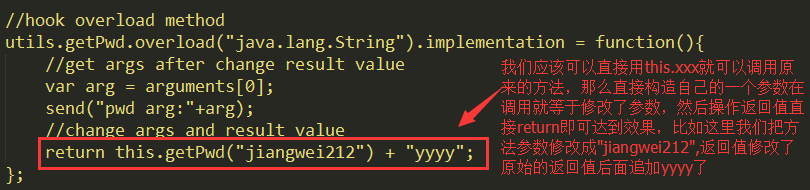
因为Frida中没有before和after方法,但是可以直接调用原来的方法其实Xposed中也可以可以直接调用原来的方法的,但是不怎么常用,只要可以调用原来的方法,那么参数和返回值就可以随意修改了,这里我们把参数改成jiangwei212,返回值后面追加yyyy了,看打印的日志:

其实这么做比before和after形式更为方便,而且可以在原始方法调用前做一些事情和后面做一些事情。
第四、构造和修改自定义类型对象和属性
我们在Xposed写外挂的时候也会遇到这种比较常见的问题,就是方法的参数不是基本类型是自定义类型,然后也想修改他的属性值或者调用他的一个方法我们会使用反射来进行操作,而在返回值的时候,想构造一个自定义类型的对象也是直接用反射实例化一个对象进行操作的。其实在这里因为js中也是支持反射操作的,所以就很简单了:

这里构造一个对象其实很简单直接固定写法$new即可,然后有了对象也可以直接调用其对应的方法即可,然后就是如何修改一个对象类型的字段值呢?这个就要用反射了:
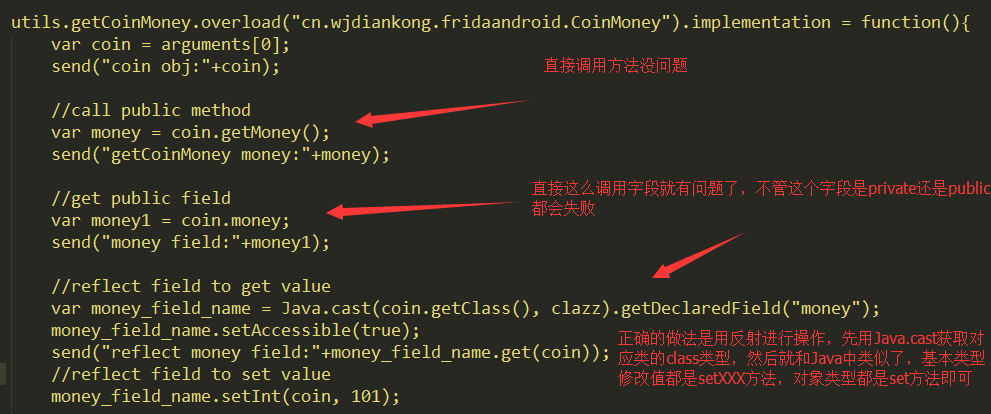
这里我们拦截了getCoinMoney方法,参数是CoinMoney类型,我们想修改他的money字段值,这时候我们直接调用他的方法没什么问题,但是如果直接调用字段值或者修改就会出现失败了,所以只能通过反射去修改字段值,不过要先获取这个对象对应的class类型,用Java.cast接口就可以,然后获取反射字段直接修改即可,这里要注意不管字段是private还是public的写法都是一样的,都是这段代码大家要注意把这段代码记住即可。我们看看hook之后的结果:
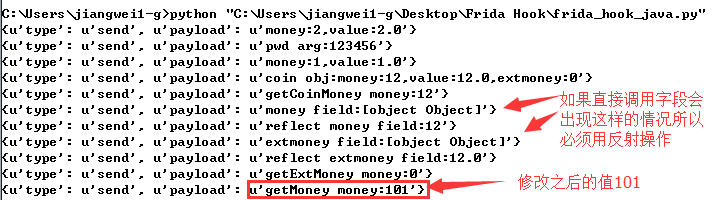
如果没有用反射去操作直接获取字段值打印就是object了。
第五、打印方法的堆栈信息
我们在破解过程中有时候通过抛出异常来打印堆栈信息跟踪代码效率会更高,Xposed中操作很方便直接Java代码用Log.xxx方法打印堆栈信息即可,但是在Frida中有点麻烦了,因为他是js代码不好操作,第一次想到的办法就是自己写一个打印堆栈信息的类然后弄成一个dex之后,把这个dex注入到程序中,因为Frida支持把一个dex文件注入到原始程序中运行的,注入之后在需要打印堆栈信息的方法中调用这个dex中的那个方法就可以了。具体怎么注入本文不多介绍了。当时觉得这种方案太麻烦了,那么还有其他方案吗?其实还是有的,因为我们既然可以构造一个对象那么为什么不直接构造一个Exception对象呢?其实操作很简单,首先我们用Java.use方法获取类型变量:var Exception = Java.use(“java.lang.Exception”);然后是js中支持throw语法的,直接在需要打印堆栈信息的方法中调用即可:
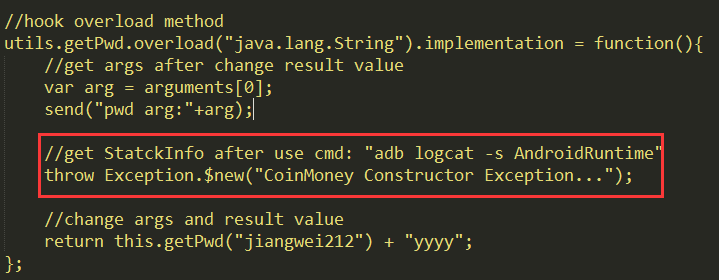
不过这个是真得抛出异常了,没有捕获住,所以程序崩溃,我们在开发Android应用的时候如果程序崩溃了最快的查看异常信息的方法就是用日志过滤方式:adb logcat -s AndroidRuntime
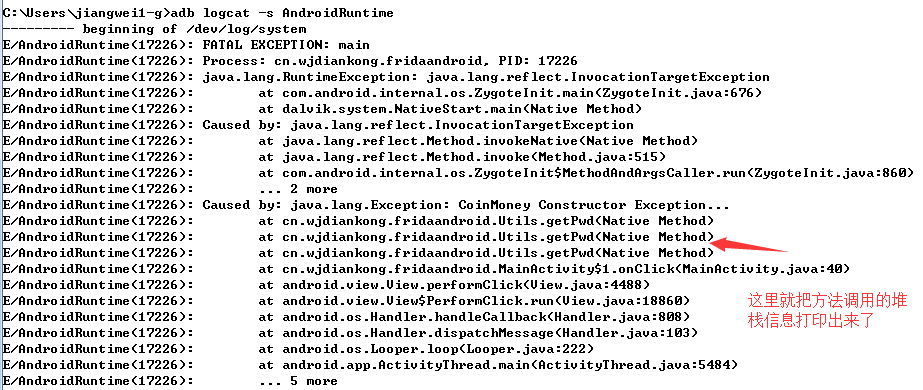
这样我们就把堆栈信息打印出来了,其实这里可以看到这个是真的一个崩溃异常了,因为没有catch所以直接用系统崩溃日志就可以查看了。这种方式最简单粗暴了。对于跟踪代码非常有用的。
到这里我们就把所有可能遇到的情形Java层hook操作都介绍完了,主要包括以下几种常见情形:
第一、Hook类的构造方法和普通方法,注意构造方法是固定写法$init即可,获取参数可以通过自定义参数名也可以直接用系统隐含的arguments变量获取即可。
第二、修改方法的参数和返回值,直接调用原始方法传入需要修改的参数值和直接修改返回值即可。
第三、构造对象使用固定写法$new即可。
第四、如果需要修改对象的字段值需要用反射去进行操作。
第五、堆栈信息打印直接调用Java的Exception类即可,通过adb logcat -s AndroidRuntime来过滤日志信息查看崩溃堆栈信息。
总结:记得用Java.use方法获取类的类型,如果遇到重载的方法用overload实现即可。
四、Native层Hook操作案例分析
下面继续来看Frida更强大的地方就是hook native代码,说的强大不是因为功能,而是便捷程度,我们之前hook native可能用Cydia比较多,但是都知道Cydia和Xposed一样都有兼容问题,环境安装配置太麻烦了,而Frida还是只需要几行js代码即可搞定,这里hook native还是用两个案例介绍:一个是hook导出的函数,一个是hook未导出的函数,通过获取参数和修改返回值来演示,这里我们不自己写native代码了,直接用之前破解快手的数据请求的so文件,他有一个函数在底层获取字符串信息,还有一个是最近正在研究的资讯类app的加密算法so,我们修改他的函数返回值。
第一、hook未导出函数功能
未导出的函数我们需要手动的计算出函数地址,然后将其转化成一个NativePointer的对象然后进行hook操作,那么如何计算一个函数地址呢?这个很简单只要得到so的内存基地址加上函数的相对地址就可以了。基地址获取直接查看程序对应的maps文件即可:

相对地址直接用IDA打开so文件就可以查看,比如这里我们通过静态分析之后想hook这个sub_5070函数:

然后我们F5查看函数对应的C语言代码查看参数信息:

这里看到是三个参数,那么计算了后的实际地址就是0x7816A000+5070=0x7816F070,不过这个地址不是最后的地址,因为thumb和arm指令的区分,地址最后一位的奇偶性来进行标志,所以这里还需加1也就是最终的0x7816F071,这一点很重要不管使用Cydia还是Frida都要注意最后计算的绝对地址要+1,不然会报错的:
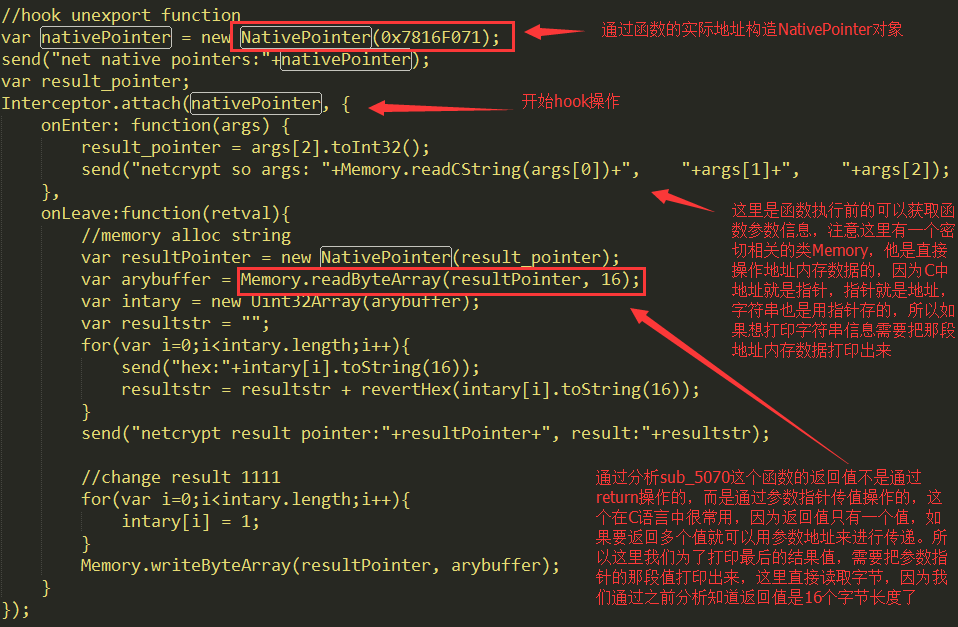
这里hook之后有两个回调方法一个是进入函数之前,一个是执行完之后,这个和Xposed非常类似了,我们打印参数,不过这个和之前Hook Java层就不一样了,因为在C中大部分都是和地址指针相关,特别是常见的字符串信息,我们如果要正确的打印字符串值就需要借助Memory系统类来通过指针获取字符串信息了,这个类非常重要,在后面修改返回值也是用它写内存值的。我们先看看这个函数原始返回值是什么:

这个是加密之后的值了,然后我们获取到参数了,而通过IDA分析之后发现这个函数最终的结果不是通过return来返回的,而是通过第三个指针参数返回的,因为C中有一个参数传值功能,就是直接操作指针就可以传回结果,这个在C中经常用到,因为一个函数返回值只有一处要是一个函数有多个返回值就没办法了,所以可以通过参数指针来传递。所以如果我们想修改函数的最终结果,需要修改参数指针的内存段数据,我们先把那个内存段数据获取到打印出来,这里因为通过静态分析知道最终的结果是16个字节数据,所以这里不能在用读取内存字符串方法了,而是读取纯的字节数据:
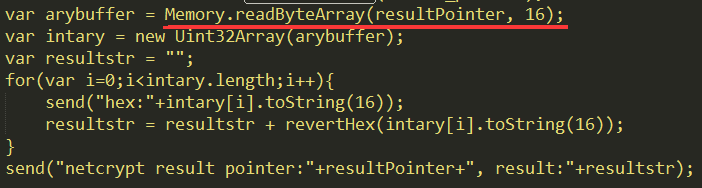
然后在把返回值修改了,返回值修改也很简单,直接重写那段内存值就可以了,比如这里修改成1111:
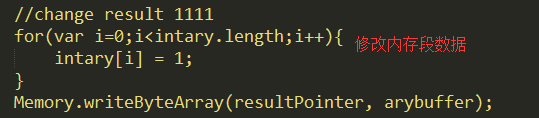
所以看到了C语言中很多地方都在直接操作内存也就是地址,特别需要借助Memory类,他有很多方法,包括内存拷贝等。具体用到的可以去官网查询:https://www.frida.re/docs/javascript-api/#memory;然后我们看hook结果:

我们hook到了他的参数信息,第一个参数是需要加密的字符串信息我们是通过Memory方法获取字符串的,因为本身这个参数是一个字符串指针,第二个参数应该是字符串长度,第三个参数是操作结果值的指针,然后看到我们获取到的结果值就是原始加密的信息。说明我们获取成功了,然后再看看我们修改之后的1111值,通过日志查看:
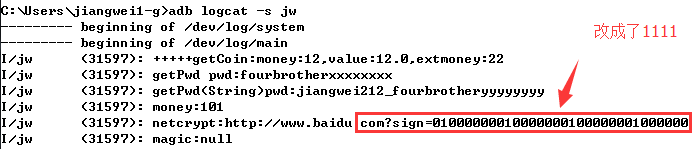
看到了在Java成通过native访问得到的签名信息已经被修改成了1111了,说明我们成功了。到这里我们就成功的,在hook native的时候一定要注意函数的绝对地址要计算对,最后一定要记住+1,函数的返回值有可能不是通过return而是参数指针传递的,操作内存的时候用Memory类即可。
第二、hook导出函数功能
这部分内容很简单了,比上面的简单是因为不需要手动的计算函数地址,因为是导出的,所以直接可以得到导出的函数名即可,因为C语言中没有重载的形式,而C++中有,所以有时候发现导出的函数名和正常的函数名前面加上了一串数据作为区分那应该是C++代码写的。有了so文件和导出的函数名就不需要构造NativePoniter了:

这个看到比上面自己手动找函数地址方便多了吧,打印参数都一样的代码了。这里通过函数名可以知道就是一个native函数了,那么他第一个参数肯定是JNIEnv指针,第二个参数是jclass类型,这个是标准的如果是静态方法第二个参数没啥用,后面的参数就是真的传递到native层的值了,比如这里Java层的方法:

那么按照上面的说明native层的函数就是4个参数了:

的确是这样的,后面两个参数才是我们想要的值,我们通过IDA查看这个函数:

然后我们用F5查看伪代码他的返回值:

用env指针调用了NewStringUTF返回一个jstring对象了,好了到这里我们先不说返回值修改的问题,先看看hook参数信息:

但是我们看到我们打印的返回值是个空也就是空指针,而如果这里我们想hook他的返回值怎么办呢?如果是一个正常的返回字符串信息,我们可以直接用Memory的方法构造出来Memory.allocUtf8String(“XXXXX”)一个内存字符串信息,然后直接返回一个指针地址即可,但是现在这里是返回一个jstring对象,其实这个我们通过查看jni.h文件可以知道jstring是C++中定义的对象:
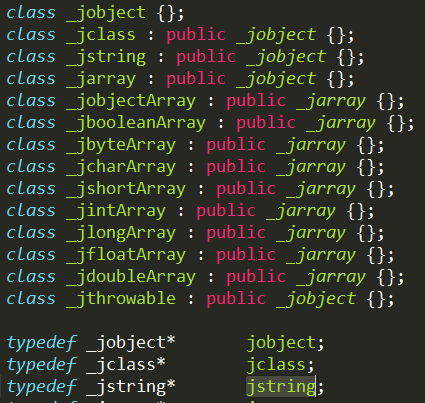
而基本类型就是基本数据类型:
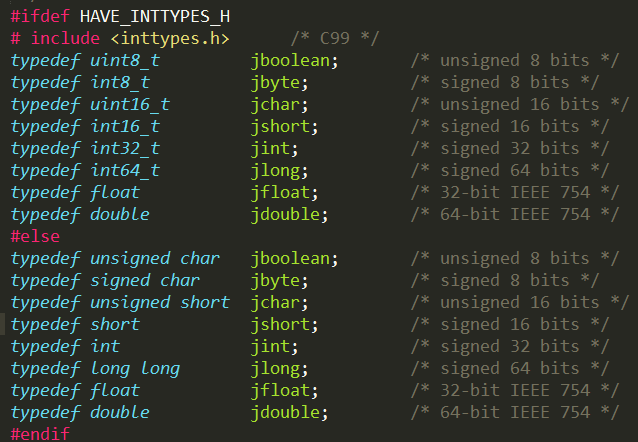
这个修改没有任何问题的,那么现在问题是修改非基本类型,比如这里的如何返回jstring对象呢?这里我能想到的一个办法就是通过获取NewStringUTF函数指针,通过NativeFunction方法获取函数,然后调用
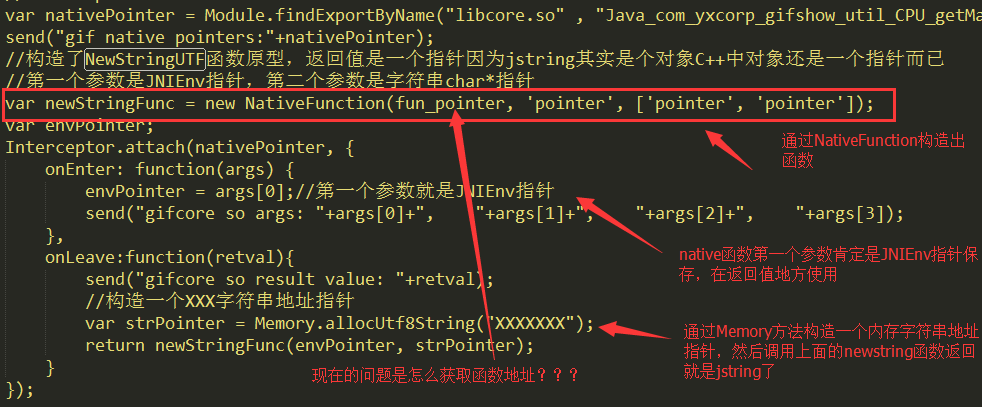
这里看到代码逻辑没什么问题,现在缺的就是NewStringUTF的函数地址了,这个因为在so中没法查看,所以怎么办呢?不着急我们在看看JNIEnv的定义:
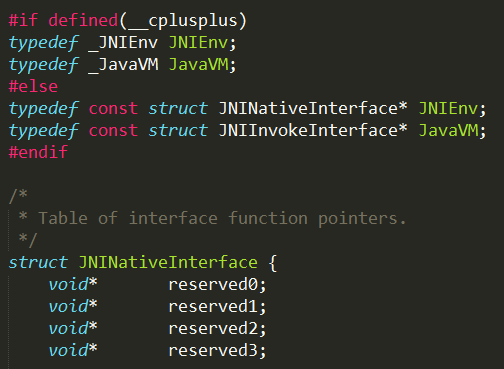
他是一个结构体,再看看那个函数地址:
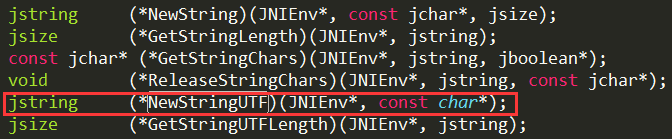
我们已经有了JNIEnv结构体指针了,每个函数指针都是int类型也就是四个字节,所以从JNIEnv指针开始依次计算就可以得到NewStringUTF函数对应的地址了。不过都说了找不到方法的时候就去官网找,JNIEnv变量其实有对应的方法,这里构造jstring方法其实很简单:
这个比找函数指正方便多了,其实env有很多方法在这里都有对应的api。
所以到这里我们发现了Frida在Hook底层函数返回jni中的类型的时候有点麻烦了,但是Cydia就不会了,因为他是Android工程,可以引用jni.h头文件的,比如我们用Cydia来修改这个函数的返回值:
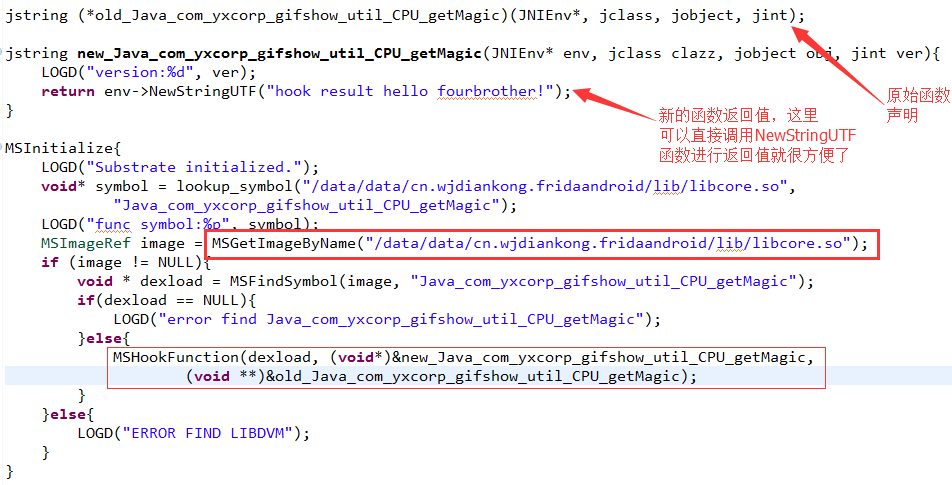
看到了吧,这样就很方便了因为是Android工程,所以可以直接应用jni.h头文件,然后直接调用NewStringUTF方法返回了,看看hook的结果:
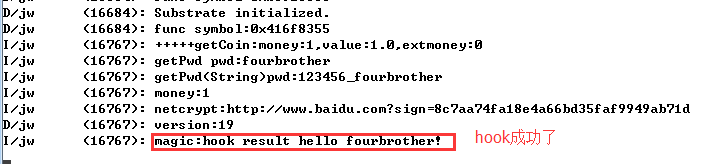
也修改成功了。所以这里看到Frida也不是万能的,要看什么问题怎么去分析了。
五、技术总结
到这里我们就把Frida常用的功能和hook常见的用法都说明完了,下面就来总结一下:
第一、Java层代码Hook操作
1、hook方法包括构造方法和对象方法,构造方法固定写法是$init,普通方法直接是方法名,参数可以自己定义也可以使用系统隐含的变量arguments获取。
2、修改方法的参数和返回值,直接调用原始方法通过传入想要修改的参数来做到修改参数的目的,以及修改返回值即可。
3、构造对象和修改对象的属性值,直接用反射进行操作,构造对象用固定写法的$new即可。
4、直接用Java的Exception对象打印堆栈信息,然后通过adb logcat -s AndroidRuntime来查看异常信息跟踪代码。
总结:获取对象的类类型是Java.use方法,方法有重载的话用overload(…….)解决。
第二、Native层代码Hook操作
1、hook导出的函数直接用so文件名和函数名即可。
2、hook未导出的函数需要计算出函数在内存中的绝对地址,通过查看maps文件获取so的基地址+函数的相对地址即可,最后不要忘了+1操作。
总结:Native中最常用的就是内存地址指针了,所以如果要正确的获取值一定要用Memory类作为辅助,特别是字符串信息。
六、Hook家族神器的对比
下面继续来看看Frida,Xposed,SubstrateCydia这三个Hook神器的区别和优缺点:
第一、Xposed的优缺点
优点:在编写Java层hook插件的时候非常好用,这一点完全优越于Frida和SubstrateCydia,因为他也是Android项目,可以直接编写Java代码调用各类api进行操作。而且可以安装到手机上直接使用。
缺点:配置安装环境繁琐,兼容性差,在Hook底层的时候就很无助了。
第二、Frida的优缺点
优点:在上面我们可以看到他的优点在于配置环境很简单,操作也很便捷,对于破解者开发阶段非常好用。支持Java层和Native层hook操作,在Native层hook如果是非基本类型的话操作有点麻烦。
缺点:因为他只适用于破解者在开发阶段,也就是他没法像Xposed用于实践生产中,比如我写一个微信外挂用Frida写肯定不行的,因为他无法在手机端运行。也就是破解者用的比较多。
第三、SubstrateCydia的优缺点
优点:可以运行在手机端,和Xposed类似可以用于实践生产中。支持Java层和Native层的hook操作,但是Java层hook不怎么常用,用的比较多的是Native层hook操作,因为他也是Android工程可以引用系统api,操作更为方便。
缺点:和Xposed一样安装配置环境繁琐,兼容性差。
以上这三个工具可以说是现在用的最多的hook工具了,总结一句话就是写Java层Hook还是Xposed方便,写Native层Hook还是Cydia了,而对于破解者开发那还是Frida最靠谱了。但是不管怎么样,写外挂最难的也是最重要的不是写代码而是寻找hook点,也就是逆向分析app找到那个地方,然后写hook代码实现插件功能。
本文的目的只有一个就是学习逆向分析技巧,如果有人利用本文技术进行非法操作带来的后果都是操作者自己承担,和本文以及本文作者没有任何关系,本文涉及到的代码项目可以去编码美丽小密圈自取,欢迎加入小密圈一起学习探讨技术

总结
本文主要介绍了Frida工具,其实原来不想介绍的,因为最近在弄一个app的协议加密,就用这个工具hook了底层函数,发现的确很好用,就整理了最常见用法的案例了,方便日后查阅也给大家提供资料,喜欢的点赞分享。
《Android应用安全防护和逆向分析》

更多内容:点击这里
关注微信公众号,最新技术干货实时推送



![[转载文章] Android中Native Hook的两种方式的区别(PLT hook与Inline hook)](http://www.520monkey.com/wp-content/themes/yusi1.0/timthumb.php?src=https://img-blog.csdnimg.cn/20200307172433500.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTAxNjQxOTA=,size_16,color_FFFFFF,t_70&h=110&w=185&q=90&zc=1&ct=1)